Structured text files
Unlike loading CSV files, structured text files requires a bit more up-front work using regular expressions.
Crafting the regular expression
Click on the Create a new format... button located on the start page
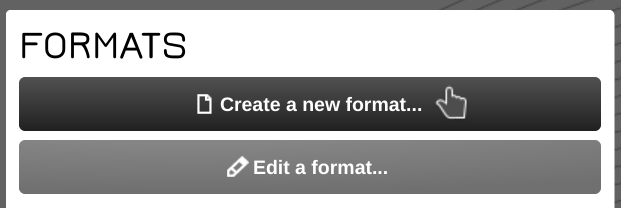
and then add a RegExp splitter by clicking the Splitters > add RegExp Splitter menus.
Enter your regular expression and validate its relevance by loading a sample of your dataset.
Tip: to validate your regular expression piece by piece, you can temporarily finish it by (.*) to have the end of the rows being matched by this catch-all group.
Click on the File > Local files... menus and select one of the dataset log file.
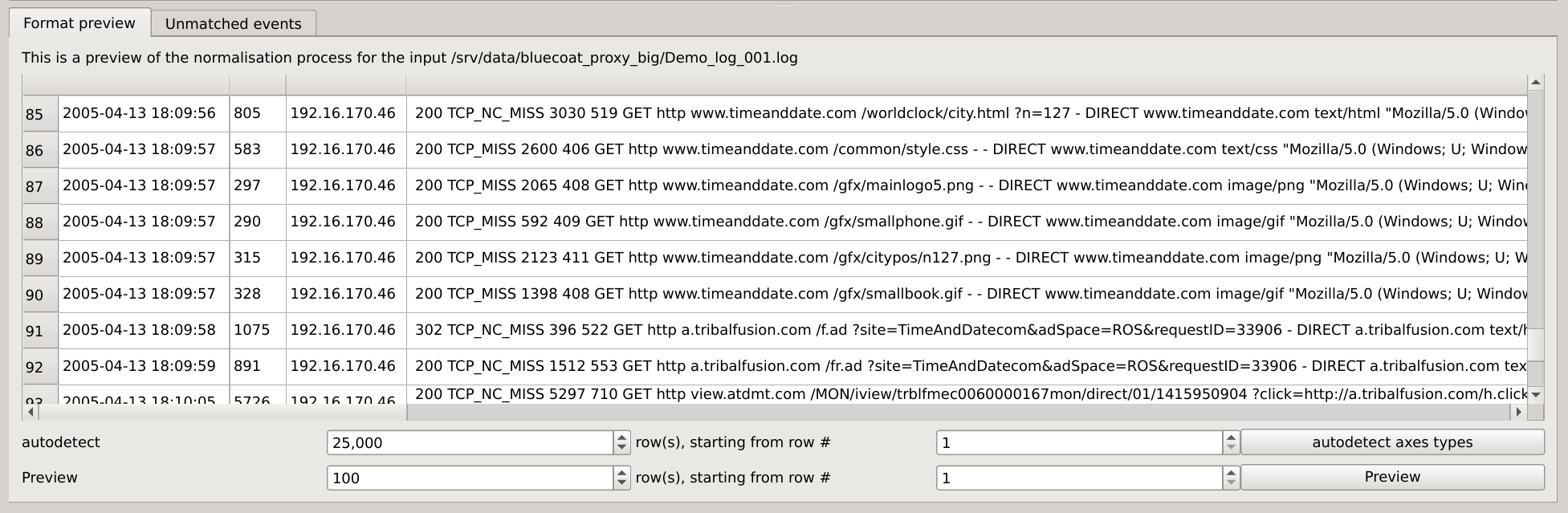
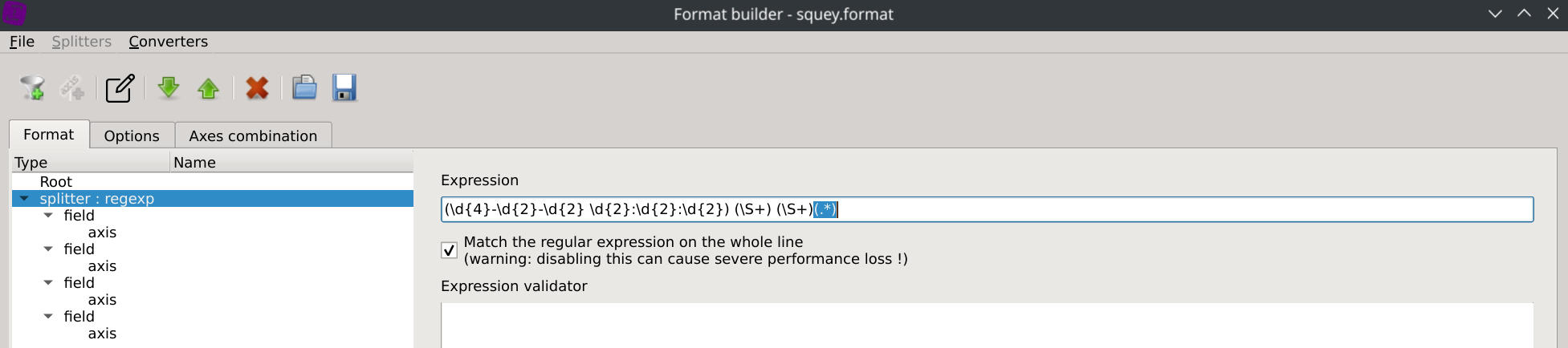
Update your regular expression and reload a sample of the dataset until you’re done.
Specifying columns name
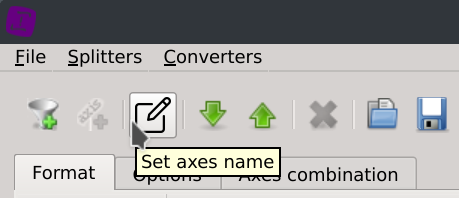
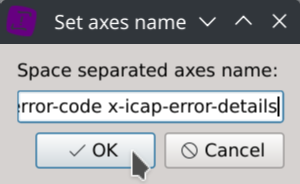
Click on the Set axes name toolbar button and enter your column names in the text dialog.
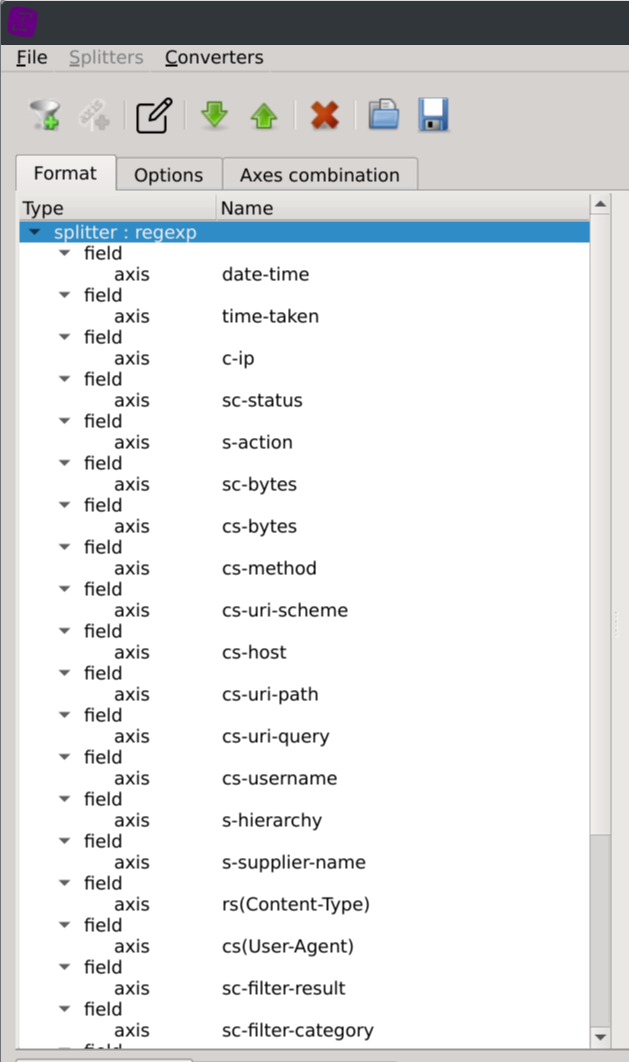
Autodetecting columns type
Click on the autodetect axes types located in the bottom right corner of the dialog.

Saving the format file
Finally, save the parsing format file in the directory of the dataset with the same name of the dataset and add the .format extension (eg. if your dataset is named dataset.txt, name your format dataset.txt.format).
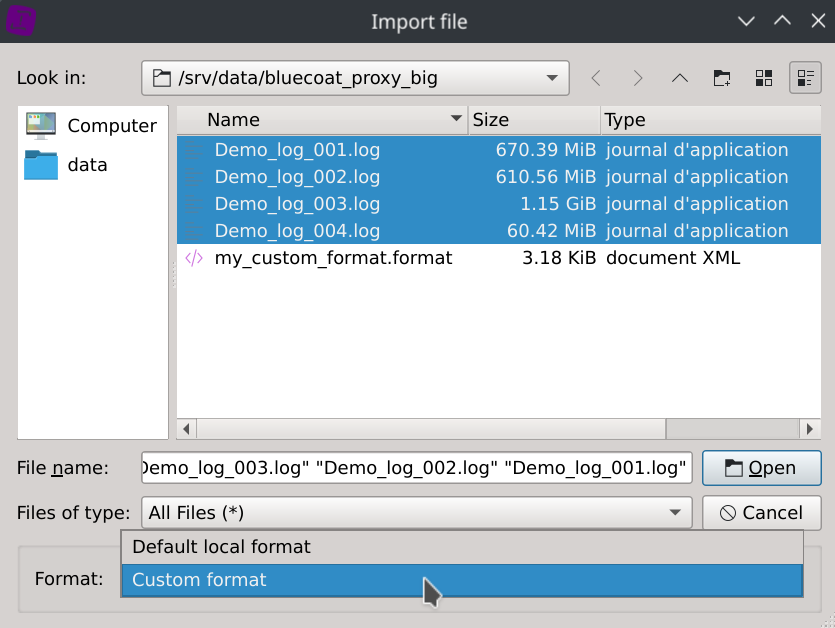
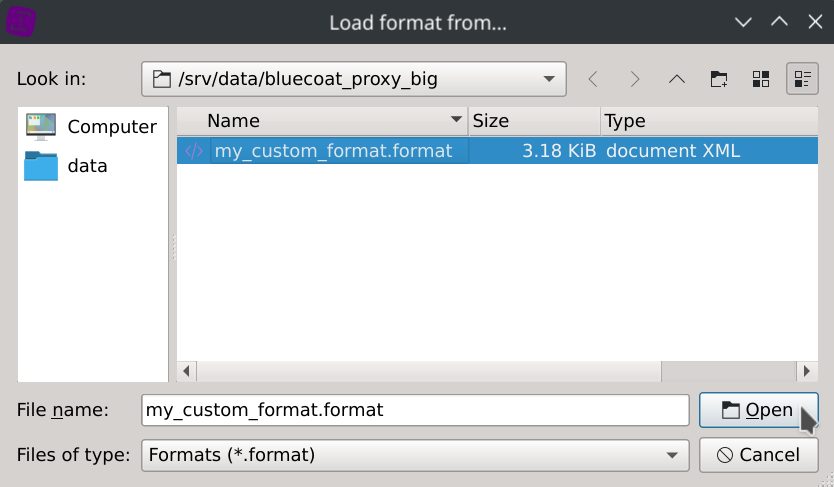
Note that squey.format could also be used as catch-all name that will automatically match any dataset (that’s handy for datasets composed of several files). If your format name doesn’t match your dataset name, you will have to explicitely select it during loading time by selecting Format: Custom format option located in the bottom of the dialog and another dialog box will ask you to locate it on the disk once clicking the Open button. This allows you to use several different formats with the same dataset.
Loading the dataset
Click on the Local files... button located on the SOURCES section of the start page and select the dataset log files.

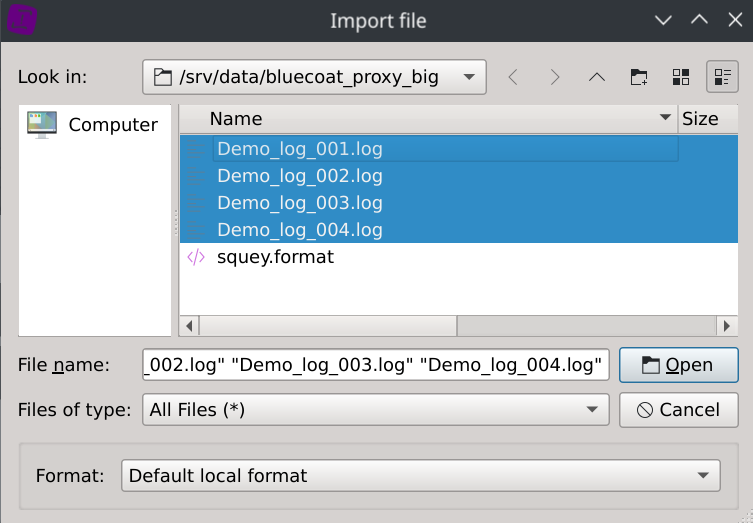
Select Format: Custom format instead of Format: Default local format option if your format file has a fancy name.